The IT Infrastructure Security Guide for managers

We’ve seen a significant rise in cyber attacks in previous years. Cyber security become one of the main topics for managers within infrastructure and software engineering. It will become even more complex as most companies transition from own infrastructure setups to cloud/SaaS services based on public facing services or public (cloud) platforms. A lot of companies still have a hard time grasping how cyber security actually works and fits into their organization.
Are you a manager facing challenges safeguarding your company’s data and assets or want to improve security on multiple fronts? This article is for you. The ultimate IT infrastructure security guide with a clear hands-on steps including detailed examples.
We’re putting multiple years of IT infrastructure management experience in a billion dollar grade Enterprise IT infrastructure environment within the Insurance/Banking industry on the table so everyone can benefit and improve their cyber security.
Disclaimer: the goal of this article is to help guide managers who want to understand the bigger picture and/or seek general guidance concerning IT infrastructure security. This is a view on the subject based on own experience. Always seek detailed advice via a security consultant or partner. Details presented in this article are examples and do not represent real-life details from companies I’ve worked for obvious security reasons.
Security Model
IT infrastructure security starts with structure. Let’s create a structure that gives us the bigger picture to start the security journey and make sure we cover all aspects needed to lay a proper foundation for any implementation that would be required.
We’ve used an industry standard for this, OWASP v2 (model is mainly used for assessing security maturity). A slightly deviated overview model that makes more sense and easy to follow the hands-on logic throughout this guide.
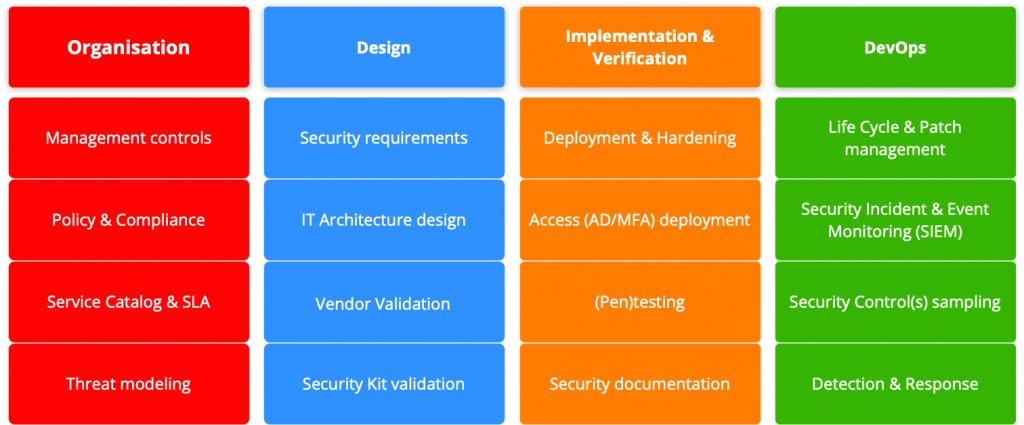
Epic 1: Organisation
Management controls
The first and foremost question starting with IT security is: who is taking decisions regarding IT security?
It’s important to understand that an environment where money and politics come in to play, you need to separate security management from business management. It basically means that a company needs to structure itself in a way where security is a separate piece of the organisation which doesn’t report to any business manager or management team that is steering the actual business.
The reason for this is simple: management for business rather wants to cut security as it is usually a burden. They want to make money as their KPI is set based on revenue. Security usually costs money and doesn’t deliver any visible customer value. Therefor it’s usually barely funded and managers will pressure security to take shortcuts in order for business to thrive. Leaving your business vulnerable and only takes one severe hit putting your company’s existence at risk.
Putting it in a separate security organisation led by a CISO (Chief Information Security Officer) reporting directly to the CEO with proper funding means you disconnect the power play from the business and security is given a true mandate to act according to your set compliance/security rules.
The goal is to make sure security in your organisation has proper mandate and funding to keep the company and its business safe at all times.
Here is a simple example what that would look like:
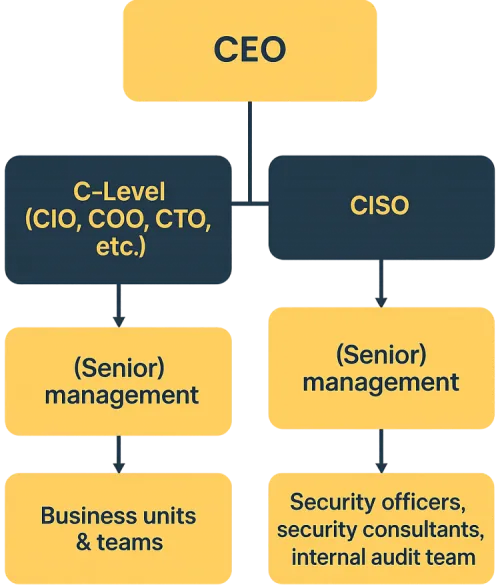
This organisation model shows a clear disconnect between reporting lines for business and security. Security can check the business without having to risk any severe influence.
Side note: in some Enterprise companies the internal audit team is also independent from anyone else and reports directly to the CEO to mitigate any risk of influence.
Vendor management
Part of your management controls is your vendor management. The hard part of vendor management is the due diligence to make sure your vendor doesn’t add any extra risk exposure to your company.
In a connected world we integrate systems with our vendors. If these vendors don’t uphold the same or better security standards, you basically have no clue regarding your risk exposure. Plus the fact that you don’t know if they’re upholding these standards in 1 year or 3 year without periodic checks.
Right to audit
It’s recommended to make sure any contract with a vendor that is significant to your business has a so called Right To Audit clause included.
As the name suggests, that clause gives you the right to actually audit the vendor whenever it’s required. In Enterprise companies this practice is normal and usually a third-party audit company is involved to perform that actual audit and check if your vendor is operating within the required standards. These reports also act as evidence if anything goes wrong.
It keeps you safe from unsecure external components and mitigates circumstances like being exposed to things like Island Hopping (explained later in article).
Don’t go overboard. A vendor delivering your coffee beans doesn’t need this clause in its contract. Focus on vendors that are integrated with your systems and may obtain some form of privileged access.
What is Island Hopping?
One of the main reasons why you want that right-to-audit clause is something in cybersecurity called Island Hopping. This is what it looks like:
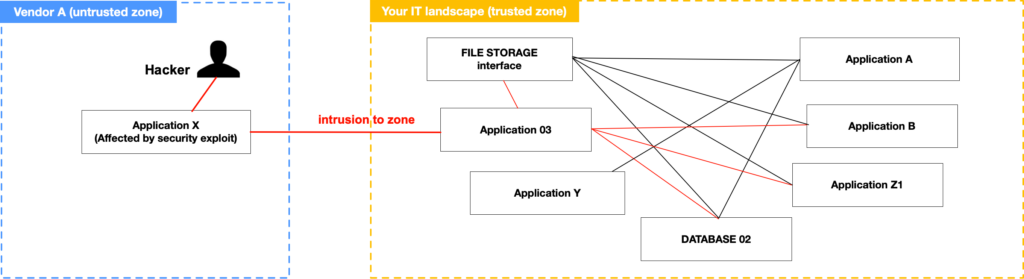
Island hopping is a sophisticated cybersecurity threat where attackers bypass defenses by exploiting vulnerabilities in third-party partners or suppliers connected to your organization. Instead of attacking you directly, they infiltrate smaller, less secure networks from your third-party vendors. They’ll use these connections to gain access to your critical systems or data. This technique often involves phishing campaigns, malware deployment, or lateral movement within interconnected networks.
Best Practices to Prevent Island Hopping:
-
Conduct regular security assessments of third-party vendors and partners.
-
Implement strict access controls and limit third-party privileges.
-
Require multi-factor authentication (MFA) for all external connections.
-
Monitor network activity for suspicious lateral movement or anomalies.
-
Create response plans that include vendor-related breaches.
Policy & Compliance
Policy and compliance are essential for maintaining a secure and well-governed IT infrastructure. Security policies provide clear guidelines on how systems, data and resources should be used and protected. Compliance ensures adherence to legal, regulatory and industry standards. It’s one of the most important tools to manage requirements and understanding between managers within the business and the internal security organisation, specifically security officers.
Service Catalog (SLA)
A Service Catalog is a database list of all IT services an organization offers, such as network access, data storage, or security tools. It explains what each service does, who can use it, and how to request it. This helps all relevant stakeholders within the company to ensure transparency, streamline operations and control access to resources. By keeping the catalog updated, organizations can improve efficiency. It enhances security and compliancy with company policies.
CIA triad
Part of your SLA is based on something called a CIA rating (rather known as CIA triad) . It’s an acronym which stands for the following:

Important note: they are in order of importance! (C)onfidentiality is always more important than (A)vailabilty. Please be mindful about this when you decide on implementations. Being not available for a few hours is still better than data leaked, stolen or lost.
A further explanation regarding these three components:
- Confidentiality ensures that sensitive information is accessible only to authorized individuals, protecting data from unauthorized access or breaches.
- Integrity focuses on maintaining the accuracy and reliability of data, ensuring it is not altered, corrupted, or deleted without proper authorization.
- Availability guarantees that systems, applications, and data are accessible when needed, minimizing downtime and ensuring business continuity.
How does the CIA rating work?
To rate the elements of the CIA triad, organizations typically assign scores from 1 to 4 based on their importance to specific systems or data. This scoring helps prioritize security measures by identifying which aspects require the most stringent protections.
-
Confidentiality: Rate confidentiality based on how sensitive the information is and the impact of unauthorized access. For example, highly sensitive financial or personal data might score a 4, indicating a critical need for protection, while public-facing data might score a 1 as confidentiality is less critical.
-
Integrity: Evaluate integrity by considering how damaging it would be if the data were altered or corrupted. Systems requiring highly accurate and trustworthy data, such as medical records or research data, may score a 4. Less critical systems, where occasional discrepancies are tolerable, might score lower
-
Availability: Rate availability by assessing how essential it is for the system or data to remain accessible. For instance, systems supporting real-time operations or customer services often score a 4 due to their high uptime requirements. Conversely, non-essential systems may receive lower ratings.
Together, these three principles provide a solid framework for safeguarding IT systems against threats, making them essential considerations for managers tasked with securing their organization’s infrastructure. Also this really helps defining this in your Service Catalog so all stakeholders from the business and security side know what kind of security and risk is involved.
Threat modeling
Blast Radius
In an IT landscape, blast radius refers to the actual defined (= component and asset level) impact by a specific incident.
Blast radius is a dependencies game. As a manager you need to fully understand the level of impact within anticipated incidents and balance it with proper resilience measures.
Outcome example
Zero-trust principles
Segregation of Duties (SoD)
Segregation of duties (SoD) is structuring your company in a way that there is a strict segregation of distributing tasks and responsibilities among different individuals and/or departments to prevent any single entity from having too much power or influence over a specific asset or process.
It basically results in check-and-balances. No single person can execute an important change or disruption by themselves. They at least one or several other people (with different incentives) to execute anything of real significance that could result in risk exposure for the company.
From an organisational perspective, this is probably the most important risk mitigation fundamental you must have in place.
Regulated privileged access
Privileged access refers to the elevated permissions granted to specific users or accounts that allow them to perform sensitive actions, such as managing systems, accessing critical data or configuring security settings. Within the context of SoD, it’s essential to ensure that no single individual has excessive control over multiple critical functions.
For example, the person responsible for approving financial transactions should not have the ability to process them.
By monitoring privileged access, organizations can maintain checks and balances, reduce insider threats and ensure compliance with regulatory requirements. Implementing strict controls around privileged access is an important step toward strengthening overall IT governance and internal security while balancing the needs within the operation itself.
Microsegmentation
Microsegmentation is an approach to network security that enables organizations to create granular, isolated segments within their IT infrastructure to better control and protect data flow. Unlike traditional network segmentation, which divides networks into larger zones (like subnets), microsegmentation operates at the workload or application level, allowing managers to enforce security policies tailored to specific assets.
This method minimizes the risk of lateral movement in case of a breach, as attackers are confined to the compromised segment rather than gaining access to the broader network.
The first step is to define the IT landscape as a whole and the dependencies of your application stack within that landscape, painting the scope of segments you actually are dealing with. The goal is isolate the application stack as much as possible where it basically operates by itself or through specific gateways where security policies are actively enforced and monitored.
Verification & Auditing
Verification and auditing are fundamental components of “never trust, always verify.” In a zero-trust architecture, continuous verification ensures that every user, device and application attempting to access resources is authenticated and authorized. Regardless of whether they are inside or outside the network perimeter.
This approach eliminates implicit trust and enforces strict access. Auditing complements verification by providing a detailed record of all access attempts, changes, and activities within the system. Regular audits allow organizations to identify anomalies, detect potential security breaches, and ensure compliance with internal policies and regulatory standards. Prioritizing verification and auditing within a zero-trust enviroment is essential for maintaining visibility, accountability, and resilience in your IT landscape.
Business continuity plan (BCP)
Nothing in life and security is 100%. So when you did all things right but disaster shows its face with you being in the worst scenario, there is still that one tool you need in place: the business continuity plan (BCP). It ensures an organization can maintain operations during disruptions like cyberattacks or system failures. For IT infrastructure, it identifies critical systems and outlines procedures for disaster recovery, backups, and failover mechanisms to minimize downtime. Regular testing and updates keep the plan effective against evolving threats.
It’s the least fun topic for sure but very necessary.
Epic 2: Design
Security requirements
Within the design process of any application, a security officer needs to be involved with a specific goal in mind: set the security requirements (based on CIA rating and other compliance requirements) and ensure those requirements are met within the production deployment of the delivered solution.
IT Architecture design
Technical security start with a design where IT security is not an afterthought. A well-designed architecture ensures that security measures are integrated into every layer. From data storage to user access, while supporting scalability and operational efficiency. Investing in proper IT architecture design helps prevent vulnerabilities, streamline DevOps and align technology choices with business goals.
Vendor validation
This only applies when the software isn’t build in-house but is build and/or licensed from a vendor. This step usually is underrated but extremely important.
Vendor validation means that your vendor is involved in the design process as a check-and-balance. You’re using software ‘as intended’ but software used at scale can hit its limits or capabilities you’re not aware of. The vendor knows those capabilities and limits which the delivered solution can operate in a safely and compliant manner.
Without this validation most vendors will drop supportability/liability once you have a critical situation and the existing design doesn’t match what they intended to deliver.
Make sure you and your vendor are on the same page and they’re aware of the design and its implementation. Once an incident or support request occurs, it will make your life 100x easier.
Security Kit (OWASP) validation
Within most Enterprise environments, most software used isn’t created in house but by a software vendor. Especially when it comes to IT infrastructure (no matter if it’s cloud, IaaS, PaaS) the technical deployment is not straight forward. Based on your application landscape the infrastructure needs to be tailored to specific needs. It mostly results in the software vendor needing to make changes in configuration in order for the deployment to meet requirements.
Most big software vendor nowadays have something called a security kit. It’s basically documentation on how the software should be configured in order for it to operate securely. It usually describes two things: configuration and hardening (= increasing security layers mainly protecting against intrusion).
Your business requirements can collide with these standards and changes need to be made to make it work. The changes are called deviations and need to be noted within your own security kit documentation. Those deviations also need to be presented to your software vendor in order to get their approval.
Why would you need approval/validation from your software vendor? Simple answer: contract. If you deviate from the intended use by the software vendor, they can drop support or contract obligations whenever disaster strikes. As you didn’t notify them upfront, they don’t have the full picture what’s going on and no way to determine proper action. No software vendor will help you when you have a breach and the full responsibility/damages/blame goes to your company.
In other words: improper validation exposes you to full liability on consequences as the lack of validation resembles negligence.
Design risk mitigation management
Designing risk management for IT infrastructure involves identifying, assessing, and mitigating potential threats to ensure the security and resilience of systems and data. This process starts with a thorough risk assessment to pinpoint vulnerabilities, evaluate their impact, and prioritize risks based on their likelihood and severity. Managers must then implement strategies to reduce these risks, such as deploying security controls, monitoring systems, and establishing incident response plans. Effective risk management design also includes regular reviews and updates to adapt to evolving threats and changes in the IT environment. For managers, a well-structured risk management approach is vital for protecting critical assets, maintaining business continuity, and fostering stakeholder confidence.
Epic 3: Implementation & Verification
Deployment & Hardening
Deploying and hardening a software application are critical steps in securing IT infrastructure. Deployment involves installing and configuring the application in a way that aligns with business needs, while hardening focuses on reducing vulnerabilities by applying security best practices. This includes disabling unnecessary features, enforcing strong access controls, and keeping the application updated with the latest patches. We’ll touch he most essential components of both.
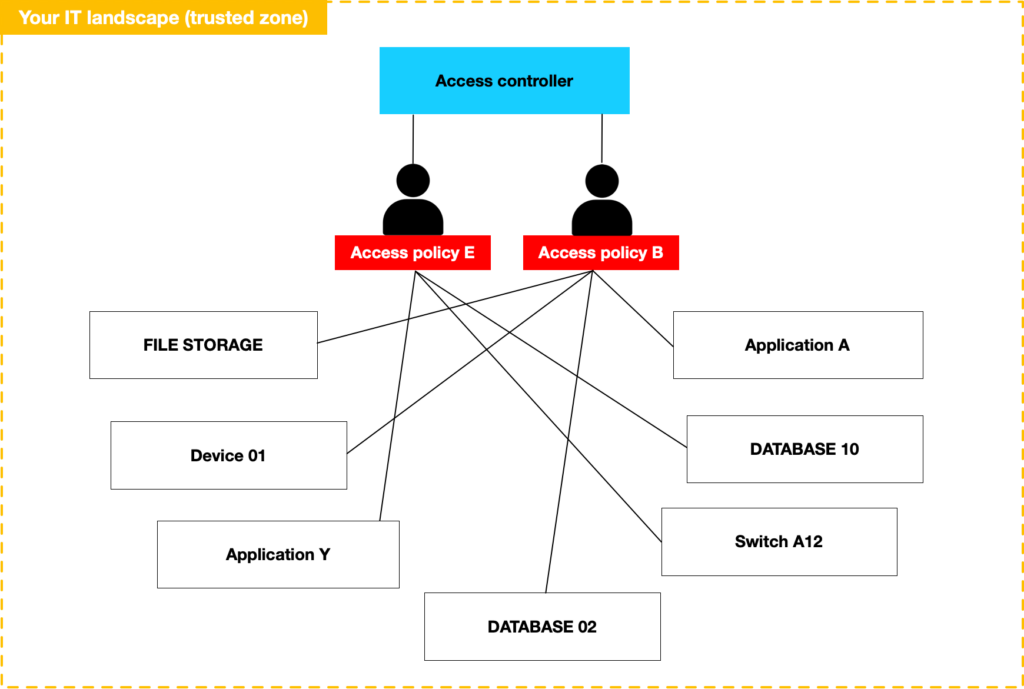
Federated Access
Federated access is a method of managing user authentication across multiple systems and organizations using a single identity within your company’s IT landscape. That landscape is also referred to as ‘trusted domain’ or ‘trusted zone’. It allows users to access various resources without needing separate credentials for each system, streamlining access while maintaining security. By relying on trusted identity providers, federated access reduces administrative overhead and ensures consistent enforcement of access policies.
Here is a simplified version what that looks like:
Pentesting
Penetration testing aka. pentesting is an assessment performed by a third-part security consultant or company. Usually performed at least once per year. The goal is to identify vulnerabilities, weaknesses, and potential entry points that malicious actors could exploit.
It gives a company clarity if and how they’re hardened against certain common attacks and/or attacks specific to the nature of their business. There basically three types of pentesting:
Black box pentest
In this scenario, an external attacker operates with no insider details. Basically someone from the outside poking around looking for entry points and any known vulnerabilities they could exploit.
Grey box pentest
This scenario is somewhat similar to black box testing. An external attacker operates as a threat but has some insider information. The attacker has some information on infrastructure and/or technical application details. The threat actor will try to use that information to attack and exploit the system.
White box or crystal box pentest
In this scenario, white box basically refers to an attack from the inside (such as an employee, contractor, etc). The attacker is actually someone with full knowledge of basically all necessary details required to attack and exploit the system.
How to define pentesting scope?
There is no ‘one-fits-all’ answer to this question. It depends on company phase, size, type of business, etc. Some tips from my own experience that might help:
- You can’t test everything in one pentest. Let the security professional collaborate with your security officer to determine the most important scenario’s to test that are real-life applicable according to statistics and standards.
- A pentest is usually a combination of scenario’s in all three categories mentioned above. The report will give a more wholesome view regarding the state of your infrastructure and application security.
- For Enterprise business, whitebox testing is more important than black/grey box testing. For startups, it’s the other way around. The reason is somewhat obvious: an Enterprise with 10,000 people has more threats from inside than a startup with 5 people. Also Enterprise usually already have a lot of security controls in place and more experience with pentesting to begin with. Startups usually also have pretty new systems with no/minimum testing of external risk exposure and usually no pentesting process in place yet.
Be mindful about the fact that pentesting is not just a test. It’s also building a process to guide this assessment properly as it will be a recurring process throughout the companies lifetime.
Security documentation
Security documentation is a comprehensive set of documents that outlines the security measures, configurations, and protocols for a software application. It includes details such as access controls, encryption methods, patch management processes, and incident response plans. This documentation is crucial for ensuring consistency in security practices, enabling teams to understand and follow established guidelines. For managers, well-maintained security documentation supports compliance, streamlines audits, and helps quickly address vulnerabilities, making it an essential tool for safeguarding the organization’s IT assets.
Epic 4: DevOps
Life Cycle Management (LCM) & Patch management
This is what I would call the basic hygiene factor of your operational platform. Software is always evolving and updates/patches are your lifeline keeping your platform safe. Now you should focus on patching. Upgrades aren’t necessarily required on short timeframes as you might not need the features or improvements introduced.
Patching is another ballgame. They come in different shapes and forms but their is basically one category to focus on: security patching.
Security patching
Here it gets a bit tricky. Security patches are rated via a system called CVSS (Common Vulnerability Scoring System). It’s a numerical system between 0-10 rating the severity of the exploit and how fast you need to patch. How this system is graded by severity:
| CVSS (v3) score | Severity level |
|---|---|
| 0.0 | None |
| 0.1 – 3.9 | Low |
| 4.0 – 6.9 | Medium |
| 7.0 – 8.9 | High |
| 9.0 – 10.0 | Critical |
To keep it practical, here are my main rules regarding patching:
- Every patch with a CVSS score above 9 should be deployed and patching completed within 24 hours after the notice/patch have been released by the vendor.
- Every patch with a CVSS score above 7 should be deployed and patching completed within 48 hours after the notice/patch have been released by the vendor.
- Every patch below 7 should go into your normal patching window, unless the item exploited has severe impact on your systems (own judgement call).
Make sure you have a recurring patch window in place regularly. A recurring patch window every two weeks would be my recommendation.
Security Information & Event Monitoring (SIEM)
SIEM is also referred to as Security Incident and Event monitoring. It’s basically your eyes and ears regarding security monitoring within your IT landscape. In short: SIEM is a mandate usually determined by your Security team and/or Security Officer which dictates what a DevOps team should forward regarding information and log events towards the security monitoring.
The SIEM documentation acts as reassurance and the actual monitoring as assurance (= you can deliver the evidence that security standards are met).
The usual flow of operations: DevOps team forwards the raw log from the application stack, another team handles the aggregation (usually the same team that controls/maintains the monitoring platform) and SecOps team actually does the monitoring. This ensures segregation of duties.
Security control sampling
Now I’ve mentioned things like assurance and reassurance. You need to understand how those correlate and why there important.
Reassurance refers to the documentation that dictates what you as an organization should be doing, like the SIEM documentation or patch management filed in your SLA documentation. Basically tells everyone how it should be done.
Assurance is the actual evidence that proofs you uphold the requirements that you documented. Basically tells everyone you did exactly what the documentation told you to do.
The Security department usually is the check&balance of the organization for security measures are actually followed. One of their biggest weapons is called a control sample.
What is a control sample? It means that Security department regularly selects an asset, like an application. The selection is random. The team responsible for that asset will be requested to send a specific statement regarding what is requested and both the assurance and reassurance. The statement usually is about the overall status and specifics that need mentioning so that the security team knows what’s going on and why certain things are done or not.
Example 1: Security team contacts the team responsible for Application X. The control sample states that they need to provide a sample regarding the state of their SIEM implementation. The team needs to send their statement plus the actual proof of monitoring (like screenshots, dump of a specific logfile, etc).
Example 2: Security team contacts the team responsible for Application Y. The control sample states that they need to provide a statement regarding their patch management. The team needs to send a statement plus the change evidence in their change management system (like the change ticket numbers from their Topdesk, ServiceNow or any similar ITSM system in use) that proof the actual date and execution runbook(s) for the executed patching.
The controls are also important for any auditor. It’s the evidence from the Security department that a check&balance mechanism is in place.
Detection & Response
Detection and Response are core components of SIEM, enabling organizations to identify and address potential threats in real time. When a threat is identified, the response process involves investigating the incident, mitigating its impact and preventing future occurrences.
Best Practices for Detection & Response in SIEM Monitoring:
-
Regularly update and fine-tune SIEM rules to reduce false positives and improve threat detection accuracy.
-
Integrate threat intelligence feeds to stay informed about emerging risks and vulnerabilities.
-
Establish clear incident response workflows to ensure quick and coordinated action during security events.
-
Conduct regular training for IT teams to improve their ability to interpret SIEM alerts and respond effectively.
-
Continuously monitor and review logs to identify patterns or trends that may signal potential threats.
-
Automate repetitive tasks, such as alert prioritization, to improve efficiency and focus on critical incidents.
Bonus: Out-of-Band management
Now what happens if you’re tightly secured and you encounter an incident and no one can reach the network due to security? That’s where out-of-band management comes in!
Out-of-band management is a method of remotely managing IT devices and systems through a dedicated channel separate from the primary network. Usually only accessible from the outside through a single component that is isolated by privileged access. This component is referred to as a ‘stepping stone server’. Technically, it typically involves using a management interface, such as a Baseboard Management Controller (BMC) or a dedicated port, which allows administrators to access and control servers, routers, or switches in restricted space of subnet(s) even when the main network is down. This setup often includes secure protocols and tools for monitoring, troubleshooting, and configuring devices without relying on the operational network.
Managers should be really mindful of who has access to this and it’s clearly defined under what circumstances this may be used.
Hope you’ve enjoyed this longread guide about IT infrastructure. If you know any manager that could benefit from this information, please share this guide! If there is any additional topics you want to see in this guide, let us know!